This is part 2 of a series on graphics engine architecture. You can read part 1 here.
Part 2 – Multi-threaded command recording and submission
When we take a closer look at any contemporary PC graphics API, we can identify two major components: One to allocate and manage graphics memory, generally in the form of textures, buffers, heaps, views/descriptors, etc. and one to issue commands to your GPU through some type of abstracted command list or device context API. These are your engine’s primary tools to communicate with your graphics driver, which in turn relays the information you give it to your graphics hardware.

In any graphics application you write you’ll want to make sure that these components are used correctly and efficiently. The general idea is that you want to interact with them as little as you can get away with, as each call into your device driver has a certain CPU-side cost associated with it. Redundant API calls can also have a negative impact on GPU performance, as various state changes can have a hidden overhead associated with them (see AMD’s excellent piece on demistifying context rolls as an example).
For a single hardware platform and a single graphics API this can get complicated already. In the era of console-like graphics development on PC where we need to take on various responsibilities the driver used to take care of, it’s hard to keep track of what minimal and efficient API usage actually means. There’s usually no single correct way of doing things, so it’s on you to experiment and figure out what works for your application and what you want to expose to the users of your library. Throw in a couple of additional platforms and graphics APIs to support, and you’ll quickly start introducing inefficient usage of your graphics APIs.
I’d like to walk you through a model of resource management and command submission where each platform has the freedom to make the right decisions for itself, regardless of what another platform might need. In addition to that I want to guarantee proper multi-threading support in this model so we can efficiently scale up our command submission code to as many threads as we’d like. Let’s start off with a look at a flexible resource management setup.
GPU resource creation and management
Let me first explain what I mean when I say “GPU resource”: A resource is any object created by your underlying graphics API which can be consumed, manipulated or inspected by some form of command submission API (e.g. a command list or device context). This definition spans a pretty wide range of items, from memory heaps, buffers and textures to descriptor tables, pipeline state objects and root signatures (or their equivalents in your API of choice).
Before we talk about submitting commands, we need to explain how we want to represent these resources when using them in our commands. For my purposes that representation comes in the form of opaque handle types.
Handles are essentially strongly typed integers. You can implement these in various ways: You could wrap an integer type into a struct, or define an enum class with a sized integer backing. The important thing here is that they’re strongly typed; you don’t want to be able to assign a handle representing a descriptor table to a handle representing a 2D texture, for example.
// An example of a strongly typed 32-bit handle using an enum class
// Note: A typedef or using statement won't work here as this won't provide strong typing
enum class Tex2DHandle : uint32 { Invalid = 0xFFFFFFFF };
// The same handle type using the struct approach
struct Tex2DHandle { uint32 m_value; };
A handle is going to become a unique representation for a given resource. The handle itself is entirely opaque and won’t be conveying any direct information about what resource it represents (as far as your application is concerned at least). This gives the underlying system the freedom to represent and organize resources in whatever way it wants; all it needs to do is guarantee that there’s a one-to-one mapping of an encoded handle to whatever backing representation it holds on to.
There are some pretty awesome benefits to using handles to represent resources. I called out one of them above: giving your engine control over how resources are represented and laid out. Another one is that you avoid the mess of trying to design a common interface to represent a resource across various platforms. You’ll sometimes see a virtual interface for resources, or shared classes which provide different per-platform implementations using preprocessor defines. These types of constructs are prone to becoming messy over time, especially when maintained by various people over various platforms. Handles don’t push you towards solutions like this, instead giving the platform the option to represent a resource as it sees fit under the hood.
Another cool aspect to handles is that it makes it easier to represent resources as pure data. There’s no API surrounding a resource. There are no methods to call which will resize a texture, or generate mips, or do some other random operation, nor will you encounter the temptation to add more bloated and unneeded operations. There are no painful situations where graphics APIs are completely incompatible (e.g. descriptor tables vs. resource views). My preference is to not even provide a way to query any type of resource properties (e.g. texture width, height, mip count, etc), with the idea being that if your application can request a resource with a given set of properties at one point during its lifetime, it should be able to store those properties somewhere in a form that fits the application if they are to be of interest later on. It’s about having a very clearly defined use case for your data, and defining very clear minimal responsibilities for your engine around that data. A resource handle can either be created, destroyed, or used in a command submission API. That’s all there is to it.
One last property of handles I explicitly want to call out is that they can remove the need for passing in pointers or references to resources into your engine, drastically improving your debugging story. A 32 bit handle has more than enough space to encode some type of implementation-specific validation information regarding what the handle is supposed to represent. This means safe access to resources at all times, and sane error reporting in case an invalid handle is passed into your engine layer.
Now that we’ve talked about handles, we can have a look at how we’ll be using them when we’re submitting work to the GPU.
Command submission: Wrangling state
Let’s clarify what we want to get out of our command submission system. We mentioned both scalability across multiple threads and minimal interaction with the underlying API already, but there are a few other things I want to achieve. One of them is a way to avoid state leakage.
Native command submission APIs (e.g. ID3D11DeviceContext or ID3D12GraphicsCommandList) are in a sense stateful. You plug pieces of state into them, or flip a handful of switches before issuing an operation such as a draw call or a compute dispatch. Any operation from setting a vertex buffer to binding a pipeline state effectively changes state around in your command API. There’s nothing inherently wrong with this, but it isn’t uncommon for some side-effects to occur because of this stored state. One of them is something we call state leakage, and this can become quite harmful the more your codebase grows.
Take the following trivial pseudocode as an example:
void RenderSomeEffect()
{
// Set up everything required to make your draw call
SetBlendState(...);
SetShaders(...);
...
// Bind a texture to slot 1
SetTexture(1, ...);
Draw(...);
}
void RenderSomeOtherEffect(EffectOption options)
{
// Draw setup
SetShaders(...);
SetDepthState(...);
...
Draw(...);
}
void RenderAllTheThings()
{
RenderSomeEffect();
RenderSomeOtherEffect(...);
}
The blend state we set in RenderSomeEffect will leak into the draw we make in RenderSomeOtherEffect, as these calls happen one after another, and RenderSomeOtherEffect does not specify a blend state of its own. In some codebases this can be desired behavior, but reliance on state leakage can often cause odd bugs when state being leaked from a system gets removed. Anything rendered in RenderSomeOtherEffect might start to rely on the blend state set in RenderSomeEffect, which could cause some very annoying bugs when RenderSomeEffect is changed or moved around.
Disallowing state leakage luckily isn’t all too difficult. The first step we need to take is to build an application-facing API in which state lifetime or state scope is well defined. The purpose of a scope is to clearly define the boundaries of when a piece of state is set, and when that piece of state gets invalidated again, similar to the concept of RAII in C++. You can define a state scope at various levels of granularity, but for this example we’ll look at two level of state scoping: a render pass scope and a draw/dispatch packet scope.
A render pass scope lasts throughout the render pass that’s currently being drawn and defines only those pieces of state that are required by all draws or dispatches being executed in that pass. This might include a set of render targets, a depth buffer, a pass-specific root signature and any per-pass or per-view resources (i.e. textures, constant buffers, etc.).
// Example render pass data. Implementation of this is up to you!
struct RenderPassData
{
RootSignature m_passRootSignature;
RenderTargetHandle m_renderTargets[8];
DepthTargetHandle m_depthTarget;
ShaderResourceHandle m_shaderResources[16];
...
};
// You could implement a scope as an RAII structure.
// Don't worry about the CommandBuffer argument, we'll get to that in a bit!
RenderPassScope BeginRenderPassScope(CommandBuffer& cbuffer, const RenderPassData& passData);
// You could also just provide simple begin/end functions
void BeginRenderPassScope(CommandBuffer& cbuffer, const RenderPassData& passData);
void EndRenderPassScope(CommandBuffer& cbuffer);
A packet scope is a scope that last for just a single draw or dispatch operation and is essentially a fully defined description of all resource needed to fully execute a draw or a dispatch (outside of what was set in the render pass scope). For draw packets this could include vertex and index buffers, a graphics pipeline state, a primitive topology, all per-draw resource bindings and the type of draw you want to execute with all parameters for that draw. A compute packet is simpler in that it just defines a compute pipeline state, a set of per-dispatch resource bindings and the type of dispatch (regular or indirect) with accompanying parameters. You could choose whether draw and compute packets are allowed to temporarily override any resources set in the render pass scope or not.
// Example of what a render packet could look like. Again, this is up to you!
struct RenderPacket
{
PipelineState m_pipelineState;
VertexBufferView m_vertexBuffers[8];
IndexBufferView m_indexBuffer;
ShaderResourceHandle m_shaderResources[16];
PrimitiveTopology m_topology;
...
};
// Example draw operation using a render packet
void DrawIndexed(CommandBuffer& cbuffer, const RenderPacket& packet);
With this setup you have a guarantee that state can’t leak out of any draw or render pass. A new render pass scope can’t begin until the last one has ended (you can easily enforce this), and ending a scope means that all state defined by that scope is invalidated. Application interaction with your engine layer is now relatively safe; it’s up to you now to guarantee safety and optimal API usage in your engine internals.
Here’s a pseudo-code example of what working with scopes could look like:
void RenderSomeRenderPass(CommandBuffer& cb, const array_view<RenderableObject>& objects)
{
// Begin with a render pass scope.
// This will bind all state provided by GetRenderPassData
// Because we're using RAII this scope will end at the end of this function body
RenderPassScope passScope = BeginRenderPassScope(cb, GetRenderPassData());
// Build render packets for our objects and submit them
for (const RenderableObject& obj : objects)
{
RenderPacket packet = BuildRenderPacketForObject(obj);
DrawIndexed(cb, packet);
}
}
Command submission: Recording and execution
So far we’ve discussed how we interact with resources and how we interact with state. To tie it all together, let’s talk about recording, submitting and executing commands.
It’s tempting to start off writing a typical abstraction layer around the command list concept. You could create a command list class with an API to record GPU operations such as submitting packets or doing memory copy operations. As hinted at in one of the pseudocode snippets above, I’d like to approach things a little different. Ideally I’d like to have my application graphics code decoupled from direct interaction with an API like D3D or Vulkan. To achieve this we can introduce the concept of command buffers.
A command buffer is a chunk of memory which we write a series of commands into. A command is a combination of a header or opcode followed by the parameters for that command (e.g. a “draw render packet command” would have a “draw render packet” opcode followed by a full render packet description). We’re essentially writing a high level program which we send off to the engine layer to interpret. This turns the engine layer into a server which processes a full sequence of commands in one go, rather than accepting commands one by one.
Building an API around this command buffer concept is very simple, as you’re at the point where you’re almost directly implementing the “video player” concept I talked about in part 1. A command buffer API can be a simple set of free functions which push commands onto your buffer. If you want to support a new platform which can do some type of exotic operation, it could be absolutely fine to introduce a new set of functions adding support for those commands only on that platform. We’re not using any interfaces, no bloated command list classes, no pImpl or other over-complicated C++ nonsense. Just a plain extensible C-like API will suffice.
void Draw(CommandBuffer& cb, const RenderPacket& packet); void DrawIndex(CommandBuffer& cb, const RenderPacket& packet); void DrawIndirect(CommandBuffer& cb, const RenderPacket& packet, BufferHandle argsBuffer); void Dispatch(CommandBuffer& cb, uint32 x, uint32 y, uint32 z); void CopyResource(commandBuffer& cb, BufferHandle src, BufferHandle dest); #if defined (SOME_PLATFORM) void ExoticOperationOnlySupportedOnSomePlatform(CommandBuffer& cb); #endif
When it comes to the engine layer implementation of command buffers, you get complete control over the translation of your command buffers to native API calls. You can re-order commands, sort them, add new ones or even straight up ignore some of them if that’s appropriate to do for your particular platform (some operations might not be supported on your platform, but could be fine to ignore!). Handles can be interpreted as your engine layer sees fit (Remember: No naked pointers in command buffers!) When implementing this, always keep in mind what your command buffer layout, your parsing logic and your resource handle resolve logic will do in terms of memory access. Keep cache coherency at as high of a priority as efficient graphics API usage, because bad memory access patterns will kill performance in a system like this.
Command submission: Going wide
Because we’re using the concept of isolated command buffers, multi-threaded command recording becomes easy (if you’re accessing any sort of shared or global state when recording a command buffer, you’re doing it wrong!). A single command buffer might not be thread-safe, but you should never find yourself in a situation where you’d want to share a command buffer between threads. Command buffers should be small and cheap, so go wide with them!
In terms of multi-threading there’s one missing piece of the puzzle though, which is multi-threaded recording and submission of native graphics API command lists (if those are available to you). To achieve this I use a model I like to call the record-stage-commit model.
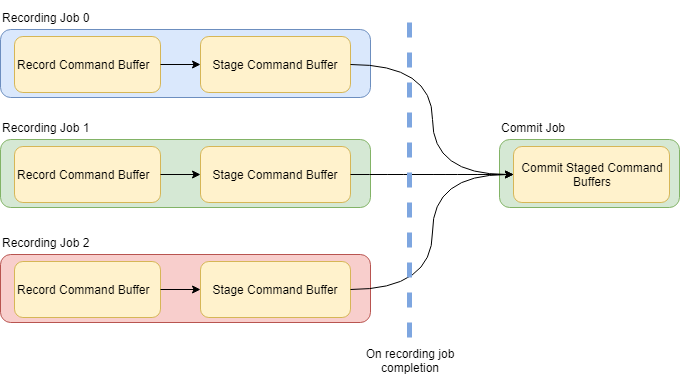
The recording aspect is what we discussed initially: recording commands into a command buffer objects using our C-like command API. The staging aspect consists of two parts: The first one is the actual translation of our command buffer into a native command list. With an API like D3D12, this would mean building an ID3D12GraphicsCommandList object. The second aspect of staging is queuing your command list for execution, together with a sort key determining when your command list should get executed relative to other command lists in your commit. It’s important to note that you should keep the staging aspect entirely free-threaded, as you want to do this on many threads at once. You could achieve this by using thread-local storage, or some form of thread-safe queue to form a list of command list and sort key pairs.
Your commit now becomes a bundled execution of all staged command lists once all recording and staging jobs are completed. The commit operation will take all queued command lists, sort them according to their sort key, and then submit them using an ExecuteCommandLists-like API. This model now gives you an API in which you can construct large graphs of rendering jobs on any level of granularity you want. You could simultaneously record all of your render passes over as many threads as you like, while guaranteeing ordering on final submission.
If you’re working with D3D11 or OpenGL, and you can’t easily build native command lists over many threads, you can still do multi-threaded recording of command buffers. Your staging step will just stage raw command buffers, and your commit step will be the one actually parsing and translating these buffers into native API calls. It’s not as ideal as the multi-threaded command recording case in D3D12 or Vulkan, but it at least gives you some form of scalability!
Addendum: Cool things to do with command buffers
Just for fun, here’s a list of other neat things you can do with command buffers:
- Save/load them to/from disk
- Build graphics code in your content pipeline! Write custom graphics capture tools!
- Dump out the last staged command buffers on a graphics-related crash for debugging
- Use them as software command bundles to optimize rendering
- Send them over the network to remotely diagnose graphics issues
- Build them in a compute shader (not sure what this would gain you, but you can do it!)
- And so much more!
There’s a lot of potential in these things for tools, debugging and optimization purposes. Go nuts!
Closing up
Whew, that was a long one! That’s all I had to share for this entry. Feel free to leave a comment here or ping me on twitter @BelgianRenderer. I’m sure there will be plenty of opinions on some of the concepts I’ve discussed here, and I’d be glad to hear them and discuss them with you. Because this post got a bit larger than I had anticipated I didn’t go super in depth into some concepts, so please feel free to ask if you have questions or concerns. I prefer explaining concepts at a higher level rather than talking about nitty-gritty implementation details. If you do want a more detailed overview of a specific section of this post, just send me a message!
Thank you for reading! See you in Part 3, where we’ll be talking about efficiently working with native API concepts!
Awesome series! This is exactly what I was looking for.
I’ve been cautiously following this series, referred by Graphics Programming weekly digest (1). Figured the disagreement reached a point where I need to express myself 🙂
> The general idea is that you want to interact with them as little as you can get away with, as each call into your device driver has a certain CPU-side cost associated with it.
This is a fairly obvious idea, but also a misleading one. Simply minimizing the number of calls is not as important as making the call costs explicit. This is what your message should be. And the render pass concept is a manifestation of this: since changing the render targets or root signatures is expensive, you expose this in the API, paving the way for the users to use efficiently.
However, the idea of software command buffers goes across the principle of explicit cost. You want to leave the right to re-order and ignore commands. You want to defer the actual recording to native API command lists to some point in the future, potentially on a different thread. This hides the cost, and makes it difficult to reason about latency.
I was also surprised to see no concern about synchronization: minimizing the stall of compute units, or CPU-GPU stalls. This is arguably more important than redundant state changes. I guess this is up for the next chapters to discuss, but I’d like to see graphics engines/API designed with this in mind. See Vulkano chapter on synchronization (2) for example.
> This gives the underlying system the freedom to represent and organize resources in whatever way it wants
You aren’t talking about the downsides of the handle approach. If the engine keeps tables of resources, it needs to keep track of the free entries and re-use them. The user has no ability to group resources by lifetime *in memory*, to improve cache utilization when accessing the resource data, or free a bulk of resources at once, etc.
> You’ll sometimes see a virtual interface for resources, or shared classes which provide different per-platform implementations using preprocessor defines.
Can’t you just have generic API that has concrete types for resources that are opaque to the user? We do this in Rust using traits and associated types (3), I’m sure something like this is possible in C++.
Overall, I think there is a wrong balance in your API between the abstraction level and the amount of freedom. Would be better to either get higher level, or make it less flexible w.r.t internal logic. Messing with individual draw packets, resolving resource handles, deferring recording – all of that is making it clear the proposed API is not performance oriented.
(1) https://www.jendrikillner.com/tags/weekly/
(2) https://docs.rs/vulkano/0.10.0/vulkano/sync/index.html
(3) https://github.com/gfx-rs/gfx/blob/d428a5d57bd793a864512bd446cbc63c630995fd/src/hal/src/lib.rs#L345
Thank you for taking the time to write this up. I was expecting a reply like this at some point, and I’ll try to do my best to address your concerns 🙂
> Simply minimizing the number of calls is not as important as making the call costs explicit. This is what your message should be. And the render pass concept is a manifestation of this: since changing the render targets or root signatures is expensive, you expose this in the API, paving the way for the users to use efficiently.
You are correct, and I’m going to elaborate on this quite a bit in the following entry. My point here was to introduce a handful of concepts which we’ll be building on, not to deeply go in to explicit detail (yet). I agree with you that my statement of minimizing API interaction hides plenty of nuance of the actual cost of individual calls, and that that is important for an end user to know.
> However, the idea of software command buffers goes across the principle of explicit cost. You want to leave the right to re-order and ignore commands. You want to defer the actual recording to native API command lists to some point in the future, potentially on a different thread. This hides the cost, and makes it difficult to reason about latency.
I wouldn’t fully agree with this. I can see where you’re coming from when talking about legacy APIs, but those are definitely not the focus of my implementation. For any reasonably modern API there is a guarantee of direct command generation on the same thread, with only submission potentially happening on a different thread. This is required to get any type of scalable multi-threaded rendering solution. It’s also not as if every single call into a native graphics API gives you a guaranteed upfront cost in terms of overhead. Whether or not you have some type of deferred execution system, you can still reason perfectly fine about potential overhead or latency. Just because you’re not making the call directly doesn’t mean that all suddenly disappears. At this point it’s probably more about communication and documentation about how a system behaves and where actual command recording and execution happens for a given platform.
Second of all I’d like to point out that this idea is not new or unproven at all, and I can’t take credit for coming up with this. In fact, many stateless renderer designs work in a way where commands are queued and then submitted at a later point, and my implementation is no different. Firaxis’ approach to stateless rendering is a very good example of this. In a presentation they did on their low level rendering engine for Civ V they explicitly address the same concerns you’re bringing up here, showing a net performance gain purely because we have such tight control over removing potential redundancy and because of additional cache coherency introduced in the lower engine layers. As for sorting and re-ordering commands, this isn’t exactly an uncommon thing in production AAA renderers either, and is usually done either way regardless of whether you use a setup like this or not. So far I haven’t had to implement any specific re-ordering for any of my back-end implementations, but the option is there if need be.
> I was also surprised to see no concern about synchronization: minimizing the stall of compute units, or CPU-GPU stalls. This is arguably more important than redundant state changes.
Again, I wanted to introduce concepts in this post first before doing a deeper dive. Don’t worry, I do have an explicit synchronization API, and you’re correct in that it’s a large topic. I made a conscious decision to not hide any synchronization away from the application as it’s crucial for the application to be able to reason about inter-queue and CPU-GPU dependency.
> If the engine keeps tables of resources, it needs to keep track of the free entries and re-use them. The user has no ability to group resources by lifetime *in memory*, to improve cache utilization when accessing the resource data, or free a bulk of resources at once, etc.
Agreed about grouping. There’s improvements which can be made here, and I’m definitely interested in exploring a better way of declaring lifetimes. So far it hasn’t been much of a problem as points of allocation and destruction of resources is fairly well known and inherently grouped. Resources generally are batch-loaded (or at least space is reserved for them) at level load, and batch-destroyed at teardown. Because of how my current implementation works, we do get some form of grouping of related resources, but this isn’t a guarantee at a higher level. An explicit lifetime API would solve this. The majority of interaction with resources at runtime also comes in the form of pre-formatted descriptor tables, which are inherently grouped by nature. At a level higher than say for example a group of textures used in a single material, or a group of materials for a single object there’s not a lot of coherency to be found in terms of resource usage. Because of the dynamic nature of real-time applications, you’re going to get random access into your resources somehow, regardless of how you represent them.
During actual rendering itself it’s quite rare to randomly create or destroy resources. Anything that does need to dynamically allocate or destroy resources is usually implemented on top of this layer (think small buffer allocators or transient resource systems).
It’s a bit unfair to associate memory layout with handles, as representation and memory layout are two different things. It’s completely possible to extend a handle-based API to do grouping based on lifetime or usage. I’ve found the argument of cache coherency when it comes to resource representation quite interesting, as there’s always another level of indirection anyway when accessing a native API resource. D3D12 gives you no control whatsoever on PC about where exactly your resources live in memory, or where it stores any resource metadata. You’re bound to miss the cache there regardless. Vulkan provides you with handles from the start, again giving that same level of indirection. I guess their allocator system can give you some additional control over memory coherency though.
> Can’t you just have generic API that has concrete types for resources that are opaque to the user?
You could implement opaque types, sure. This will often be done in C++ using the pImpl-idiom or something similar. Rust traits is something I really wish we had in the C++ ecosystem, but I guess the language is getting bloated enough as it is already.
The handle approach can give you a more compact resource implementation though, and makes things such as command buffer caching for later re-use (i.e. command bundles) a lot easier. You tend to use a lot of resources throughout a given frame, and storing a full 8-byte pointer per used resource is a massive waste of space when doing command buffers. I’m wary of using pointers in any type of cached data representation as well, purely because of the debuggability concerns. Having a deterministic handle system where handles can easily be checked for validity gives you a much more sane debugging experience in case something does go wrong. Nobody likes debugging random access violations on some random pointer you grabbed from somwhere 🙂
> Messing with individual draw packets, resolving resource handles, deferring recording – all of that is making it clear the proposed API is not performance oriented.
That’s a pretty strong statement to derive from just reading this single post. I understand your concerns, but none of the things you mention here need to directly imply deteriorated performance. I don’t even know what “Messing with individual draw packets” is supposed to mean. You’re setting up draw state one way or another, doing it with a compact packet representation doesn’t change anything in terms of efficiency and makes the experience of working with your rendering layer much more sane (IMO). I would argue that being able to linearly traverse a command buffer to do your command recording gives you plenty of benefits in terms of cache coherency and code simplicity. Deferring recording is another argument which seems to be unfounded, as the concept of deferring a record operation to another thread at a later point was only brought up in terms of legacy APIs, which are not my primary focus. Again, the concept of queueing up commands and batch-recording them right after is not new or unproven at all. We’ve been doing this for a long time now.
If we want to talk performance, we’re going to have to talk numbers. It’s easy enough to call an implementation slow and unbalanced after reading a high-level overview. I’ll see if I can set up some comparison cases at later point in time (probably in a couple of weeks or so) so we have real numbers to look at. I’ll be glad to discuss performance and implementation nuances at that point.
I appreciate you taking the time to voice your concerns, and I would love to hear any additional points you might have. I don’t know if I’ve given a full answer to your concerns, but I’ll add to this comment chain if I feel like I didn’t properly explain myself in certain cases. Some of the things you brought up will come up in future entries, as mentioned.
This is a more detailed answer than I could hope, thank you! I mostly agree with it, just citing what rubs me in the wrong way 🙂
> For any reasonably modern API there is a guarantee of direct command generation on the same thread, with only submission potentially happening on a different thread
Sure, but do you actually guarantee that behavior by the engine/API? My understanding was that you want the actual recording to be free-threaded, and thus it’s tempting (why not?) to leave that implementation detail to the engine, which could, among other things, just have an internal thread pool to do the thing, or use specific frameworks like Apple’s libdispatch to schedule that work.
> In fact, many stateless renderer designs work in a way where commands are queued and then submitted at a later point, and my implementation is no different.
I do believe that, but could you support this statement by a few links? One explanation could be that multi-core recording is *still* getting it’s way into giant rendering systems (previously tailored towards DX11) that the game industry fosters. Another – that those commands being stored are higher level than your command buffer. This is what I meant by improper balance between high-levelness and freedom of implementation – it totally makes sense to re-order the draw packets and store them, in my book, just at a slightly higher level than the command buffer abstraction you are proposing.
> You tend to use a lot of resources throughout a given frame, and storing a full 8-byte pointer per used resource is a massive waste of space when doing command buffers
My understanding is the the construction of those command buffers could be opaque to the user. They’d pass in references of resources (assuming those are opaque types), and the engine/implementation would extract the bits that are really needed for that command buffer. Say, if it’s about resource views, then the implementation would just find a descriptor set having them (or create/update one), without storing anything else about the resources in the command buffer.
> Vulkan provides you with handles from the start, again giving that same level of indirection. I guess their allocator system can give you some additional control over memory coherency though.
Exactly. They had no choice but providing opaque handles (in a C API), and they realized that users know better where the internal structures of the driver need to be allocated, so they added the allocation callbacks. I don’t think you need to repeat the same (sub-optimal) path, unless your performance overhead criteria is lower, so you can afford this.
> I don’t even know what “Messing with individual draw packets” is supposed to mean.
What I meant was re-ordering them and processing them in any non-linear way prior to encoding to the low level API.
> You’re setting up draw state one way or another, doing it with a compact packet representation doesn’t change anything in terms of efficiency
I’d argue that exposing descriptor sets *would* change something in terms of efficiency. Also, the packet representation you propose is not that compact. There is a bunch of fixed-size arrays in there, spanning across multiple cache lines, and I expect a ton of unused space (harming data cache efficiency). What’s the size of your packet? Perhaps, you’d benefit from moving the resource arrays out and only storing ranges (start .. end) in the packets themselves.
>Deferring recording is another argument which seems to be unfounded
Sorry about the confusion. I was using “deferring” in a more general sense than what legacy APIs imply. In a sense that you aren’t immediately recording the command buffers and doing them sometime later (even if on the same thread).
Sorry for the late reply on this! I wanted to find some time where I could sit down and write a proper answer, and I guess this is the first moment that was available 🙂 Got a bit occupied with SIGGRAPH (+ the ensuing plague I got afterwards).
> Sure, but do you actually guarantee that behavior by the engine/API?
It’s partially in control of the user of the API. That whole record-stage-commit thing I talked about is something that the user explicitly controls, so the engine does no magic under the hood there. The recording of a native command list is guaranteed to happen on staging of a command buffer, which should happen as close to recording of a command buffer as possible. This works on D3D12, Vulkan, and D3D11 with deferred contexts, but just cannot work on any API that doesn’t allow async recording of commands natively, hence why I brought up the whole native recording at a later stage bit. I don’t encourage it, and don’t actually do it in my current implementation, but you could if you’d want to. Your concern is completely founded there in that you’re obfuscating potential overhead though. Command buffers are also supposed to be quick fire and forget types of objects, not things you hold on to indefinitely, unless you explicitly want to use them as some sort of bundle system.
In terms of threading, the engine makes no assumptions. In our setup we have a job system which is directly exposed to the user. You write rendering code in terms of the job system. The engine won’t do any implicit threading magic for you.
> I do believe that, but could you support this statement by a few links?
Sure!
Brooke Hodgman provided a good overview of how he dealt with this in his presentation “Designing a Modern GPU Interface“.
As mentioned earlier, there’s also an overview of Firaxis’ LORE rendering engine for Civ V, although they take it to some more extreme lengths by recording the entire frame up front before submitting it.
There’s also various discussions on blogs regarding similar concepts like draw call bucketing and layered rendering and such. I won’t link them all here.
> One explanation could be that multi-core recording is *still* getting it’s way into giant rendering systems (previously tailored towards DX11) that the game industry fosters.
We’re definitely not at a point where we’re running fully scalable multi-threaded engines all over the place, but there have been some good efforts to get multi-threaded rendering going in AAA titles and elsewhere. I’ve worked on a few of them 🙂
The industry just moves slow, and getting good scaling is hard when we’re talking about PC development. On consoles we can cheat our way through some aspects of a multi-threaded rendering setup, so a lot of titles with purely a focus on console won’t invest too much time in getting a widely scalable system for PC going.
> My understanding is the the construction of those command buffers could be opaque to the user. They’d pass in references of resources…
That’s sort of what happens now. There’s still some more user-friendly constructs for building command buffers which get optimized and compacted down. The idea of directly extracting descriptors and such is interesting, and it’s definitely valid, but it defeats some of the purpose of what I want to use these command buffers for. It’s a completely legitimate way of going about it though.
> They had no choice but providing opaque handles (in a C API), and they realized that users know better where the internal structures of the driver need to be allocated, so they added the allocation callbacks.
And that makes absolute sense. As mentioned before, I definitely need to do some more thinking about resource grouping and giving a little bit more control over memory layout.
> Also, the packet representation you propose is not that compact. There is a bunch of fixed-size arrays in there, spanning across multiple cache lines, and I expect a ton of unused space (harming data cache efficiency).
Render packets are variable length when finally encoded. It’s all dependent on how many resources are being bound and what type of draw call is being issued. I only write out the data I absolute need, and any required metadata is compacted. Draw packet size and cache alignment has always been a priority, and hasn’t been a huge deal so far.
> I was using “deferring” in a more general sense than what legacy APIs imply. In a sense that you aren’t immediately recording the command buffers and doing them sometime later (even if on the same thread).
As mentioned before, that’s completely up to the user of the API. The general recommendation is to immediately stage a command buffer so it gets translated into a native command list, after which you discard the original command buffer (as I said, they’re supposed to be used in a “fire and forget” manner). There might be legitimate reasons to not do that though, so I don’t enforce anything.
Very interesting post. I’m also getting a lot out of the discussion thread. Thanks for posting and replying. Looking forward to your next installment.
1.) How do you handle actual GPU resource creation/destruction with this system? You have resource descriptors like TextureDesc which has all the needed properties (width, height etc.) and then just create empty resource without actual data in it? After initial resource creation you have separated command to upload texture data to textures? And how about shader creation/destruction?
struct TextureDesc
{
uint8_t type; // 2d, 3d or cubemap
uint16_t width;
uint16_t height;
};
struct TextureHandle
{
uint16_t index;
uint16_t generation;
};
struct UploadTextureCmd
{
TextureHandle handle;
uint8_t* data;
size_t bytes;
};
namespace API
{
IRenderDevice* vulkan_device; // Active graphics API device
TextureHandleGenerator texture_handle_generator;
void* texture_resources[256];
// RESOURCE API
TextureHandle CreateTexture(TextureDesc& desc)
{
TextureHandle handle = texture_handle_generator.generate();
void* textureResource = vulkanDevice->createTexture(desc);
texture_resources[handle.index] = textureResource;
return handle;
}
bool DestroyTexture(TextureHandle) { … }
// COMMAND API
// Textures
void UploadTexture(CommandBuffer& cbuffer, UploadTextureCmd& cmd) { … }
// Vertex, index, shader shader constant buffers etc.
void UploadBuffer(CommandBuffer& cbuffer, UploadBufferCmd& cmd) { … }
void Draw(CommandBuffer& cbuffer, DrawCmd& cmd) { … }
}
2.) Where do you store scissors, viewports etc. that don’t belong to pipeline state objects? Are these also part of the RenderPassData?
Yep, resources like textures, pipeline states, etc. all get created on the device (or whatever other construct you want to set up to handle resource storage) with all information which can be provided without having to execute any command list operations. That does indeed mean that your buffer and texture resources will start off empty, and you’ll have to do a dedicated upload. You need to do that anyway on DX12 and Vulkan, so it makes sense to surface that to your API. That leaves you room as well to decide where and when you want the upload to happen, e.g. using a dedicated DMA/copy queue.
I currently associate viewports with a render pass yes, but it could conceptually live somewhere else. I’m not specifically advocating for a monolithic render pass object which needs to control all non-draw related state, but I’m more so advocating scoping data in a way that makes sense.
Scissor rectangles are interesting in that a lot of techniques/libraries/applications will assume they can be set per draw (e.g. Dear Imgui), so I’ve set them up on a per draw basis out of convenience. Again, this could live anywhere else, but to me it made the most sense from a usability perspective.
I’m struggling to get into graphics programming, and I just wish I knew as much as you guys 😀
I just found this series of posts whilst looking for information on graphics architecture. Really well made and easy to digest! Any plans to release part 3? 🙂
Great article, however I have some questions on my mind:
1. How would you perform redundant state filtering in case of parallel command translation?
2. How would you perform resource (buffer/image) updates using API agnostic commands? The data gets consumed later, the application must ensure that the data is still available when it gets consumed – its very error prone. Otherwise, if the command returns a pointer directly to the mapped memory of the resource (directly to the destination buffer or to the staging buffer), then the command cannot be agnostic, since it must interact with the graphics backend/device abstraction layer to resolve the resource handle and return the mapped pointer.
Thanks in advance!